Deep Learning training methodologies in OpenDR
5 November 2021
Robots need to interact with their environments, make decisions and take actions in real time. This requires the use of high-performing and efficient perception models. Such models need to provide acceptable performance levels to the application at hand (also considering safety requirements in environments where robots co-operate with humans), while being able to run in (near-)real time on embedded GPUs.
Two of the most important aspects of developing efficient Deep Learning models for robot perception and cognition are the model design and its training. Lightweight Deep Learning models have found to provide a balance between high performance and real-time operation in computationally restricted environments. OpenDR developed lightweight deep learning models for object detection, and semantic scene segmentation. An example of semantic scene segmentation applied on a high-resolution video frame can be seen in Figure 1.

Figure 1: Heatmap of bicycle (with bicyclist) segmentation
Crucial role in achieving high performance in lightweight deep learning models plays efficient utilization of the training data and the use of effective training processes. Information distillation is one of the training techniques that can be used to this end. The main idea in information distillation is to use a high-performing Deep Learning model which can be formed by an enormous number of parameters (called teacher model) to guide the training of the lightweight Deep Learning model (called student model). This is commonly achieved by using the high-performing model to generate hierarchical data representations at its intermediate (and last) layers which are used as targets for training the lightweight model. A schematic illustration of this idea, as implemented by a new training method proposed by OpenDR partners is shown in Figure 2.
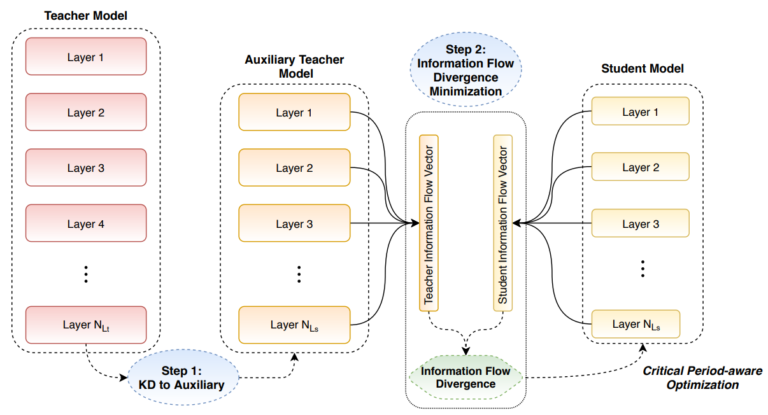
Figure 2: Information distillation used to train a lightweight Deep Learning model (student) using a high-performing and computationally complex Deep Learning model (teacher).
Another process which can be used to effectively train Deep Learning models in situations where a small set of labeled data is available, is Supervised Domain Adaptation. The main idea in Supervised Domain Adaptation is to use a high-performing Deep Learning model, trained on another, but related, task in order to, again, guide the training of the new model. This is commonly achieved by aligning the representations of the input data at the feature space defined by the outputs of a layer of the two networks using class scatter information. Partners in OpenDR showed that this process can be described by a two-view graph embedding formulation, as shown in Figure 3.
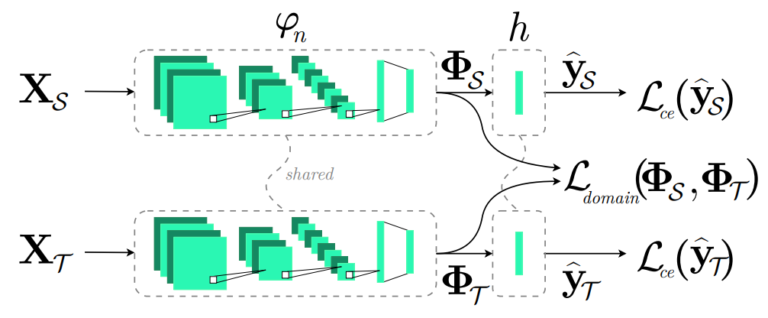
Figure 3: Supervised Domain Adaptation via Graph Embedding. Data from a large and annotated dataset (source domain XS) are used to train the parameters of the Deep Learning model, jointly with data from the problem at hand (target domain XT). This is achieved by including a Domain Adaptation loss Ldomain in the training process.
Authored by: Alexandros Iosifidis and AU team
Aarhus University, Denmark