EAGERx: An Engine Agnostic Gym Environment with Reactive Extension
26 January 2022
Reinforcement learning (RL) methods have received much attention due to impressive results in many robotic applications. While RL promises learning-based control of near-optimal behaviors in theory, successful learning can elude practitioners due to various implementation challenges.
Even when one selects the best-suited learning method, learning performance can disappoint due to several factors, such as badly chosen hyper-parameters or an unreliable implementation of the algorithm. Furthermore, a learning task can be made unnecessarily hard by incorrect specifications.
Learning a control policy is usually done in simulation for practical reasons. Unfortunately, transferring such a controller into the real world can lead to poor results due to unaccounted differences between the simulator and reality. These differences may arise due to sensor delays or inaccurate simulation of the dynamics and are collectively called the “sim2real gap”. RL methods are notorious for exploiting (or even overfitting on) these differences to maximize the simulated rewards. Consequently, the sim2real gap may lead roboticists to observe a performance gap between simulation and reality. Unfortunately, most RL methods are black box, and it is near impossible to say up front which of the challenges above is the root cause for the deteriorated performance.
One could argue: if learning in simulation causes so many troubles, why not learn directly in the real world and eliminate the sim2real gap? Real-world learning is not only prohibitively expensive but it can also introduce issues related to safety, such as damages to the equipment or human operators.
To overcome all these limitations, OpenDR has developed EAGERx (Engine Agnostic Gym Environment with Reactive extension) (see Fig. 1). EAGERx enables users to easily define new tasks, switch from one sensor to another, and switch from simulation to reality by being invariant to the physics engine. EAGERx explicitly addresses the differences in learning between simulation and reality, with essential features for roboticists such as a safety layer, signal delay simulation, and real-world reset routines. A single RL pipeline that works with both the simulated and real robots eliminates the chance for mismatches between the simulation and reality implementation. The defined task follows the OpenAI Gym interface, so one can plug in algorithms from established RL libraries (e.g., Stable Baselines) to solve the task afterward, again minimizing implementation errors.
EAGERx can be interfaced with your favorite physics engine (e.g., Pybullet, Gazebo, …), and it also supports physics simulation with a custom dynamical model. In terms of code, the real world is treated as any other physics-engine, allowing users to effortlessly switch from simulation to the real world (an example is shown in Fig. 3). Also, EAGERx favors composition over inheritance, hence improving user-friendliness so that the addition of robots, sensors and other objects to an environment is reduced to a one-liner of code or a single click in the graphical user interface (see Fig. 2). Finally, EAGERx leverages the perception modules of OpenDR by allowing users to add nodes that preprocess raw sensor images. Learning from low-dimensional observations can favorably reduce training times by orders of magnitude.
Despite significant interest in reinforcement learning in recent years, most of the works with RL in robotics are done in simulation only. We hope that EAGERx will lead to more success stories in the real world.

Figure 1: Overview of the features of EAGERx
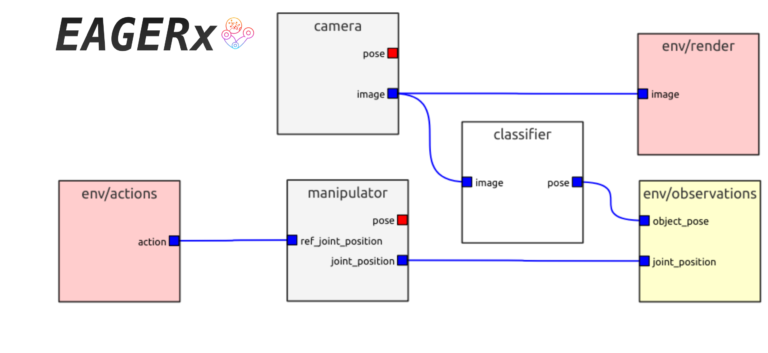
Figure 2: EAGERx’s graphical user interface allows users to add robots, sensors and other objects to an environment with a few clicks. Here, we visualize the environment used for a task where we manipulate an object using a manipulator and camera. We do not sense the object directly, but infer its pose by passing the rgb images of the camera through a pre-trained classifier.
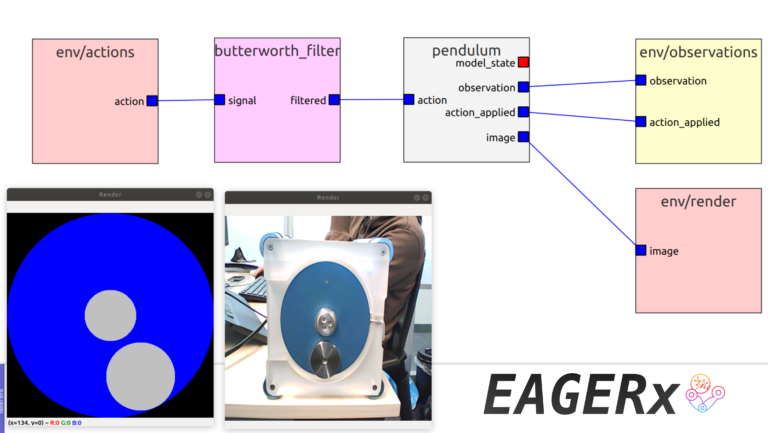
Figure 3: EAGERx’s render capabilities are also agnostic, so that changing the physics-engine also seamless switches the render source corresponding to the selected physics-engine. Here, we use the same agnostic environment to fuse experience gathered on a real pendulum with that of the simulated one for faster training, while learning more realistic policies.
Authored by: Bas van der Heijden, Jelle Luijkx, Laura Ferranti, Jens Kober, and Robert Babuska
Delft University of Technology, Netherlands