OpenDR: Towards Intelligent Autonomous Robotics
powered by Deep Learning
8 July 2021
Almost everything we hear about artificial intelligence today is thanks to deep learning. This category of algorithms have been proved to be immensely powerful in mimicking human skills, such as our ability to see and hear. To a very narrow extent, it can even emulate our ability to reason. These capabilities power Google’s search and translation services, Facebook’s news feed, Tesla’s autopilot features and Netflix’s recommendation engine and are transforming industries like healthcare and education. Deep learning has achieved tremendous performance jumps in the last decade in several computer vision and machine learning tasks achieving in many cases super-human performance. It is evident that deep learning is one of the most promising research directions we should target in order to achieve autonomy in robotics, that is, to build robots that are able to act without human guidance and control. The application of deep learning in robotics is the major challenge for the next decade as defined by numerous researchers that leads to very specific learning, reasoning and embodiment problems and research questions that are typically not addressed by the computer vision and machine learning communities.
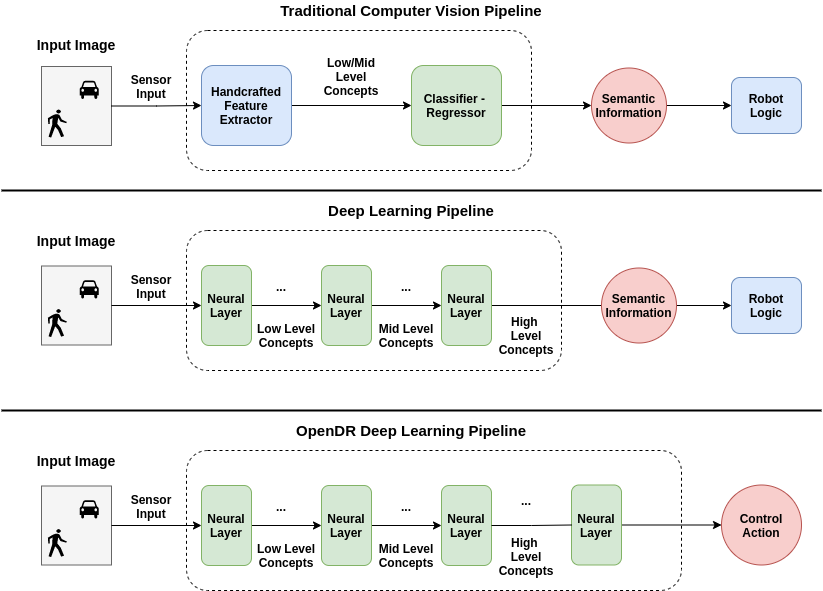
Fig. 1: In a traditional computer vision pipeline we employ a hand-crafted feature extractor, i.e., an algorithm designed using human knowledge and intuition, to extract useful information out of the raw input signal. This information is then fed into a machine learning model to extract useful high level semantic information that is subsequently fed into a hand-crafted robot controller that implements the core logic of a robot. The actual learning part of this process is restricted to the machine learning model. On the other hand, deep learning completely replaces the hand-crafted feature extraction process with a series of learnable neural layers, allowing for learning how to perform feature extraction in an end-to-end fashion. OpenDR aims to further integrate robotics into deep learning by also considering the final task that has to be solved by the robot and learning models that can actively sense their environment and issue the appropriate control commands.
The core of deep learning is to build models that are able to use raw sensor information and perform inference. This is illustrated in Fig. 1. In deep learning we stack several different neural layers, somewhat inspired by the way the brain processes information, in order to gradually extract more abstract concepts. For example, for a computer vision problem, early layers extract information regarding the edges that appear in the input image, while later layers compose this information to build more abstract concepts, e.g., humans, cars, etc. In this architecture we typically do not introduce strong prior knowledge, i.e., we do not enforce how to perform this kind of processing. In contrast, we use deep learning to learn how these neural layers should be adjusted in order to perform the task at hand. We commonly refer to this process as end-to-end learning to highlight the fact that the whole architecture can be adjusted automatically for all the layers involved, i.e., from the input to output, just by observing the input data and the ground truth (correct) answers. This is in contrast with traditional computer vision pipelines where these information processing layers were designed according to prior knowledge and are kept fixed, i.e., they cannot be adjusted to extract new information from the data without human intervention (e.g., by designing new hand-crafted features). Although this end-to-end training approach has been successfully followed for different tasks ranging from speech recognition to computer vision and machine translation in the last decade, the big challenge for the next years is to successfully apply the same end-to-end training and deployment approach for robotics, which means to build models that are able to both sense and act using a unified deep learning architecture, as shown in the last row of Fig. 1. That is, in robotics it is often not enough just to understand what we are seeing, but we also need to know how to act in the situation we are currently in.
Indeed, despite the recent successes in robotics, artificial intelligence and computer vision, a complete artificial agent necessarily must include active perception. The reason follows directly from the definition of an agent as an active perceiver if it knows why it wishes to sense, and then chooses what to perceive, and determines how, when and where to achieve that perception. The computational generation of intelligent behavior has been the goal of all AI, vision and robotics research since its earliest days and agents that know why they behave as they do and choose their behaviors depending on their context clearly would be embodiments of this goal. To be able to build agents with active perception towards improved AI and Cognition we should consider how deep learning can be smoothly integrated in the robotics methodologies either for building subsystems (e.g., active object detection) that try to solve a more complex task (e.g., grasping) or for replacing the entire robotic system pipeline leading to end-to-end trainable agents that are able to successfully solve a robotics task (e.g., end to end deep learning for navigation). However, integrating deep learning in robotics is not trivial and thus it is still in its infancy compared to the penetration of deep learning to other research areas (e.g., computer vision, search engines, etc.).
OpenDR‘s ambition is to reverse the current situation described above by removing the obstacles that prevent deep learning from being efficiently and successfully integrated into robotics pipelines. This will be done by developing a modular, open and non-proprietary deep learning toolkit for core robotic functionalities that will provide advanced perception and cognition capabilities. By doing so, it will help meet the general requirements of robotics applications in the areas of healthcare, agri-food and agile production. The concept of OpenDR is to exploit and apply the clear path that has been proposed in the last years for designing and training lightweight deep learning architectures for real-time applications with limited computing and/or memory resources. The project is positioned somewhere in the middle of the spectra ‘idea to application’, ‘lab to market’: while certain of its R&D topics are close to ideas (e.g., end-to-end trainable active perception is at its scientific infancy), others are close to application (e.g., deep learning for robot navigation in autonomous driving). The objective is to achieve a high technology readiness level for the whole OpenDR toolkit and test the entire learning and simulation methodology in real scenarios.
Authored by: Nikolaos Passalis and AUTH team,
Aristotle University of Thessaloniki, Greece