Learning Kinematic Feasibility for Mobile Manipulation through Deep Reinforcement Learning
11 March 2022
Mobile manipulation is a key research area on the journey to both autonomous household assistants as well as flexible automation processes and warehouse logistics. Although impressive results have been achieved over the last years, there are still multiple unsolved research problems. One of the major ones being that most current approaches separate navigation and manipulation due to the difficulties in planning the joint movement of the robot base and its end-effector (EE). This restricts the range of tasks that can be solved and constrains the overall efficiency that can be achieved. Typically, the tasks that a robot is expected to perform are linked to conditions in the task space, such as poses at which handled objects can be grasped, orientation that objects should maintain or entire trajectories that must be followed. While there are techniques to position a manipulator to fulfill various task constraints with respect to the kinematics of the robot, based on inverse reachability maps, performing such tasks while moving the base still remains an unsolved problem.
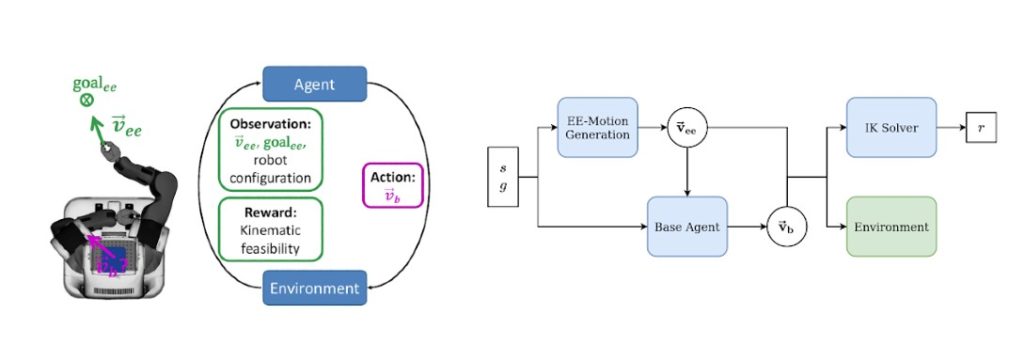
The overarching goal of the OpenDR project is to create a modular, open and non-proprietary toolkit for core robotic functionalities by harnessing deep learning to provide advanced perception and cognition capabilities. Within the first version of this toolkit, we provide a method to generate kinematically feasible movement for the base of a mobile robot while its end-effector executes motions generated by an arbitrary system in the task space to perform a certain action. This decomposes the task into generation of trajectories for the end-effector, which is typically defined by the task constraints, and the robot base, which should handle kinematic constraints and collision avoidance. This separation is beneficial for many robotic applications. First, it results in high modularity where action models for the end-effector can easily be shared among robots with different kinematic properties. Therefore, there is no need to adapt the behavior of the end-effector for different robots as the kinematic constraints are handled entirely by the base motion control. Second, if the learned base policy is able to generalize to arbitrary end-effector motions, the same base policy can be used on new unseen tasks without expensive retraining. The overall methodology is depicted in Figure 1.

We have demonstrated our approach on a variety of tasks on multiple different mobile robots. The tasks consist of simple planned pick & place actions based on object poses and predefined grasp poses as well as more complex articulated object handling based on gripper motions learned from human demonstrations. Exemplary snapshots from the execution of these actions are shown in Figure 2.

Figure 2: We demonstrated our approach on an HSR, a PR and a TIAGo robot on a series of mobile manipulation tasks in the simulated Gazebo environment.
We further evaluated the transferability of our approach to real world settings by performing the same tasks from above on our PR2 robot.


Figure 3: Real world experiments on a PR2. Using our approach the robot base navigates the environment to enable the gripper to perform an independently planned pick&place action.
The pre-trained models for the kinematic feasible robot base navigation are available in the OpenDR toolkit. We are currently extending our method to account for collisions with the environment to increase flexibility and usability to a broader range of settings.
We hope that our approach will serve as a foundation for many follow-up approaches, especially in the realm of reinforcement learning for mobile manipulation tasks. These can then focus on goal oriented end-effector trajectories while leaving base navigation and kinematic feasibility to our trained agent
Authored by: Tim Welschehold, Daniel Honerkamp, and Abhinav Valada
Albert-Ludwigs-University Freiburg, Germany